Fastest BatchNorm Kernel on LeetGPU
Optimizing CUDA code to perform Batch Norm from scratch
In this article, I present a CUDA kernel implementation for computing the Batch Normalization (Batch Norm) operation.
Batch Normalization is a widely used technique in deep neural networks that helps accelerate convergence during training and improve numerical stability. It operates channel-wise across a batch of data, using two learnable parameters: (gamma) and (beta).
For each channel, we compute the mean and standard deviation as:
The input is then normalized and scaled as follows:
This normalization step first makes mean 0 unit variance, and then allowing the network to learn optimal rescaling and shift through the parameters and .
Understanding the Algorithm
The question in this problem is, how do you figure out what part to parallelize?
Do you parallelize across samples or across channels?
Well, parallelizing only along samples is awkward because the per-channel mean/variance
need reductions across the batch (samples) for each channel. You could use atomicAdd and keep
accumulating in global memory but that's slow and basically sequential (since they're highly
contended by many threads).
So you need to parallelize across channels, maybe assign a block to 1 channel. But this is also
suboptimal. Your data has shape [N, C], but since data must be flattened in CUDA arrays, the
data looks like
[Sample1 Channel1, Sample1 Channel2, ..., Sample1 ChannelC, Sample2 Channel1, ...]
Imagine your reads now. Adjacent threads are reading from locations in memory C addresses apart.
That means you cannot make use of coalescing each memory access! Coalescing really speeds up
programs because the hardware then just loads in several adjacent memory addresses together.
The technique is to make use of both parallelization. You have 2D blocks rather than 1D blocks.
On the x-axis threads vary across channel. On the y-axis, by sample. So, adjacent threads as per the
x-axis now load [Sample1 Channel1, Sample1 Channel2, ..., Sample1 Channel WarpSize] which is coalesced.
You can also now apply a reduction pattern to reduce over channels so actually the number of global reads a
thread has to do becomes ceil(N / blockDim.y) instead of N.
Note: A reduction pattern is a pattern you can apply to any commutative and associative operator. You can
imagine, if + is the operator, then we re-write: (a + (b + (c + d))) as ((a + b) + (c + d)). I.e., the even
threads add their neighbors, then the threads divisible by 4 add threads 2 locations away and so on. This
is not actually optimal, because for larger problems where the reduction spans multiple blocks and warps,
whole warps eventually become useless (be skipped) but they still occupy the hardware. So, people actually
write this in reverse, you sum elements from blockDim.y/2 elements away, then blockDim.y/4 elements away
and so on, and then the threadIdx.x == 0 has your result
Once we have the mean element and sum of squares of inputs, the answer is really simple
as we just apply the formula!
#define TILEX 32 // warp dim #define TILEY 32 __global__ void batch_norm(const float* input, const float* gamma, const float* beta, float* output, int N, int C, float eps){ __shared__ float Ms[TILEY][TILEX]; // mean sum __shared__ float Ss[TILEY][TILEX]; // square sum int sample = threadIdx.y; // only 1 block so blockIdx.y = 0 int channel = threadIdx.x + blockDim.x * blockIdx.x; // Every thread sums the samples that have (sample % blockDim.y) == threadIdx.y float m_sum = 0; float s_sum = 0; for(int i = sample; i < N; i += blockDim.y){ if(channel < C){ // coalesce across C reads float v = input[i * C + channel]; m_sum += v; s_sum += v * v; } } Ms[threadIdx.y][threadIdx.x] = m_sum; Ss[threadIdx.y][threadIdx.x] = s_sum; __syncthreads(); // Reduction Pattern for(int j = blockDim.y / 2; j > 0; j >>= 1){ if(threadIdx.y < j){ // Only accumulate in threads < j, eventually 0 contains the sum Ms[threadIdx.y][threadIdx.x] += Ms[threadIdx.y + j][threadIdx.x]; Ss[threadIdx.y][threadIdx.x] += Ss[threadIdx.y + j][threadIdx.x]; } __syncthreads(); } // Load repeatedly used params into registers float mean = Ms[0][threadIdx.x] / static_cast<float>(N); float inv_std = fmaxf(Ss[0][threadIdx.x] / static_cast<float>(N) - mean * mean, 0.0f); inv_std = rsqrtf(inv_std + eps); float g = (channel < C) ? gamma[channel] : 0; float b = (channel < C) ? beta[channel] : 0; // Write back out for every sample for(int i = sample; i < N; i += blockDim.y){ if(channel < C){ output[i * C + channel] = g * ((input[i * C + channel] - mean) * inv_std) + b; } } }
Results
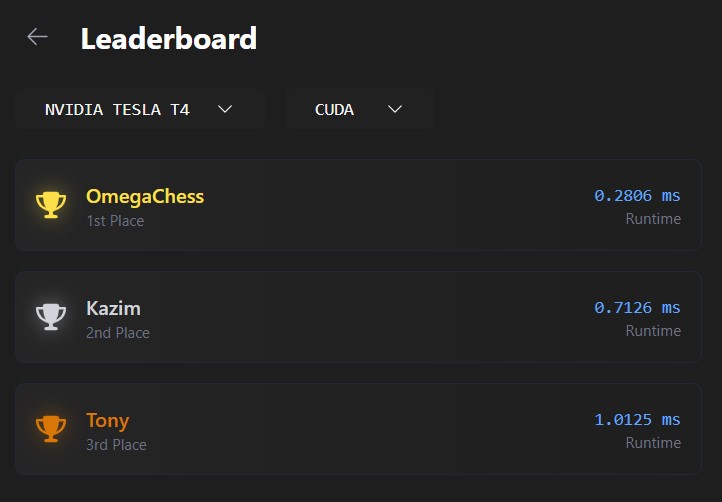
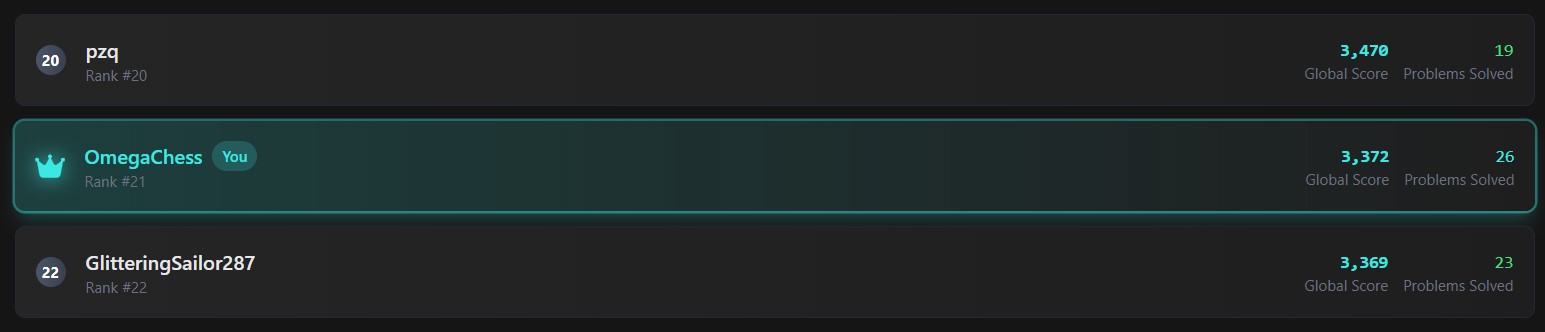
In the end, my kernel achieved the fastest time on LeetGPU's BatchNorm benchmark 2.54× faster than the next entry, written by the platform's top-ranked user. This also boosted my overall LeetGPU ranking to #21 globally.
More Stuff
If my cuda work was interesting, please check out my github for more:
CUDA Practice Repo
I hope you enjoyed reading the article
Any feedback is greatly appreciated! (Form is broken, message me on LinkedIn)